



AI 개발, 학습데이터의 중요성
AI 산업을 관통하는 단 하나의 키워드는 ‘학습데이터의 중요성’이다. 2021년 3월 앤드류 응(Andrew Ng)교수가 학습데이터의 중요성을 강조한 이래, 데이터 중심의 인공 지능(Data-Centric AI) 개발은 업계 표준으로 자리 잡았다. AI 성능을 높이는 데는 알고리즘과 코드 개선보다, 더 좋은 학습데이터를 구하는 작업이 훨씬 효과적이라는 맥락이다. 본 기고문에서는 AI 학습데이터 구축의 핵심 기술과 사례를 소개한다.
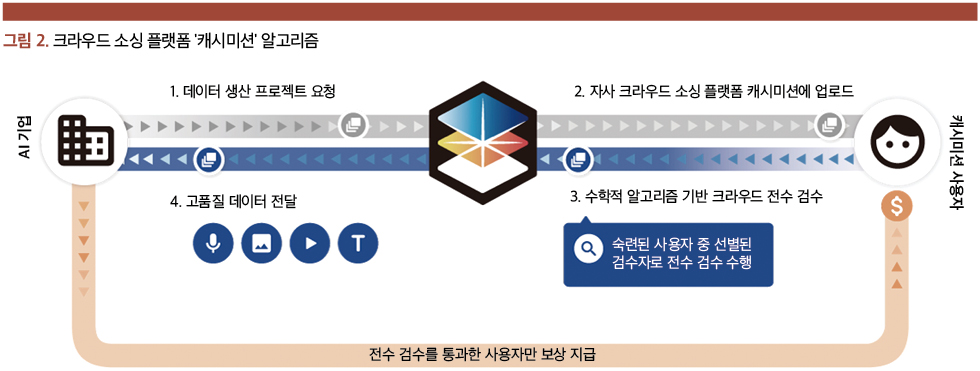
크라우드 소싱 플랫폼의 장점
데이터 구축 산업은 본질적으로 매우 노동집약적이다. 수십 만건의 원천데이터를 수집하고 가공하는 과정에서 상당한 노동력이 투입되기 때문이다. 셀렉트스타는 이 점에 착안에 크라우드 소싱 플랫폼 캐시미션을 런칭했다. 기업 입장에서는 작업자를 상시 고용 및 유지하지 않고 데이터 구축 업무 전반을 용역할 수 있기에 많은 비용과 시간을 절감할 수 있다.
데이터 품질 관리 노하우 및 솔루션
데이터 구축 서비스의 경쟁력은 납품 데이터의 품질에서 온다. 불특정 다수의 노동력을 활용하는 크라우드 소싱 과정에서 일관된 작업 수준을 유지하기 어렵기 때문이다. 셀렉트스타는 데이터의 일관성을 확보하기 위해 회사 설립 초기부터 국내 유일 전문 가이드팀을 운영하고 있다. 교육 자료, 작업 상세 기준, 작업 참여를 위한 테스트 문항 등을 문서화하는 조직이다. 크라우드 워커는 작업 가이드라인 숙지를 확인하는 테스트를 통과해야만 작업에 참여할 수 있으며, 작업 중에는 정답이 정해진 ‘함정 문제’를 풀며 어뷰징 여부를 검증받는다.
또한 데이터 구축 플랫폼은 AI 기업 요청에 따라 일반 크라우드가 아닌 전문 인력 섭외 및 고용, 정보 보안을 위한 작업 인력 인하우스 파견 및 관리 역량 또한 갖추고 있어야 한다. 이밖에도 프로젝트 착수부터 최종 데이터 납품까지 모델 성능에 영향을 줄 수 있는 희소한 엣지케이스를 고려하고, 솔루션을 제안하는 컨설팅 업무 또한 데이터 구축 서비스 플랫폼의 역할이다.
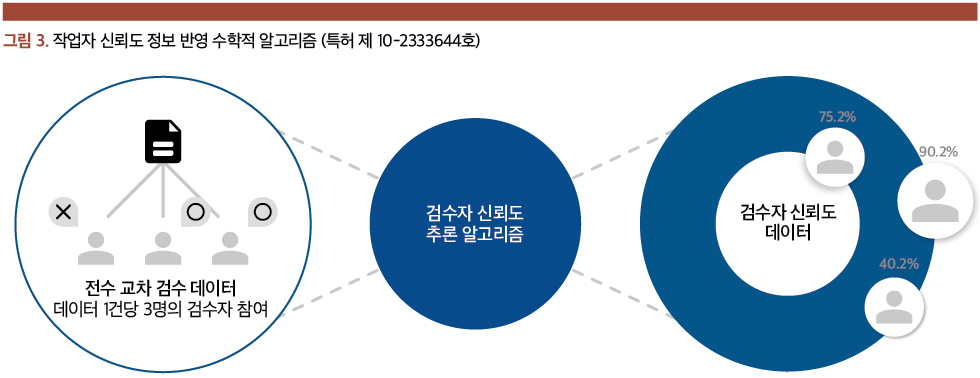
작업자 신뢰도 정보 반영 수학적 알고리즘 특허
셀렉트스타는 데이터 품질 관리를 위한 10건의 기술 특허를 보유하고 있다. 본 특허는 크라우드 작업자의 작업 능력을 수치화하여, 이를 검수 결과에 반영하는 방법이다. 예를 들어 하나에 데이터에 대해 검사자 2명이 ‘통과’ 1명이 ‘불통’을 제출할 경우, 단순 다수결이 아니라 작업자의 신뢰도 데이터를 의사 결정에 반영하는 알고리즘이다. 이때 크라우드 작업자는 작업 신뢰도를 측정하는 별도의 작업을 수행할 필요가 없다. KAIST 수리과학 박사진이 개발한 수학적 알고리즘을 통해, 일정 분량 이상 작업을 제출하는 시점에 비교 검사로 작업 수행 능력을 자동으로 예측한다.

반자동 Bounding BOX 라벨링 특허
본 특허는 이미지 내 물체 주변 Bounding BOX를 그리는 유저 인터페이스(UI)에 관한 내용이다. 통상 라벨링 작업에선 라벨 대상과 Bounding BOX 사이의 간격이 좁을수록 양질의 데이터가 생성된다. 셀렉트스타에서는 라벨 작업자마다 발생하는 편차를 줄이기 위해, 설정된 값에 따라 반자동으로 보조 Bounding BOX를 생성한다. 작업자는 객체 경계를 두 Bounding Box 사이에 위치함으로써, 보다 정확하고 일관된 라벨링 작업이 가능하다.
한국어 혐오 표현 데이터셋 KOLD
KOLD(Korea Offensive Language Dataset) 데이터셋을 소개한다. KOLD는 KAIST 연구진과 셀렉트스타가 협업하여 구축한 한국어 혐오 표현 데이터셋으로, 네이버 뉴스와 유튜브 플랫폼 등에서 수집한 4만 429개의 혐오 댓글과 그에 대한 주석으로 구성돼 있다. 수 천명의 크라우드 작업자들이 제공된 댓글에서 혐오 키워드를 발췌하고, 일정한 기준에 따라 인종 젠더 지역 등으로 혐오 대상을 분류했다. 수집한 데이터 전량에 대해 최소 3회 교차 검수를 진행하면서, 혐오에 대한 공중(公衆)의 주관을 일관되게 반영할 수 있었다.
KOLD는 대부분 영어로 구성된 자연어 처리(NLP, Natural Language Processing) 분야 학습데이터 시장에서, 소수 언어인 한국어 혐오 표현을 수집·가공한 양질의 정제 데이터 셋이다. KAIST 연구진에 따르면, 연구 결과 한국어 혐오 표현의 대상 그룹 분포가 기존 영어 데이터 세트와 크게 다르다는 사실이 발견됐다. KOLD를 한국어 처리 모델 학습에 활용하면 인공지능 번역, 독해, 챗봇 성능을 효과적으로 높일 수 있다.
KOLD 데이터셋과 관련 논문은 오는 12월 아랍에미리트 아부다비에서 자연어 처리(NLP, Natural Language Processing) 분야 세계 최고 권위 국제 학술대회 ‘EMNLP’에서 공식 발표될 예정이다.
